
A little about Project Banana…
Project Banana was an exploratory project I worked on at Val Town to help allow for concurrent request handling for our nodejs/fastify servers processing user Val requests. It was based on a file-system based process management idea that I had which would allow us to introduce concurrency while letting us reuse our fastify/nodejs backend with minimal changes.
Previously all user requests would go to one of our nodejs servers, which are single-threaded, and that server is bottlenecked both in that we would need to hit the database on each request to know if a current warm worker could be used, and that even if we got rid of needing to hit the database, we were still limited by the fact that our nodejs server could only forward a single request at a time.
But with some clever tricks, it’s possible to do better, and keep things simple-ish!
Bottlenecks!
If you’re not super interested in the nitty gritty, and just want to skip to the fun part, check out the next section. There we get to more fun technical details like folder file system locks and using processes-as-files with inotify!
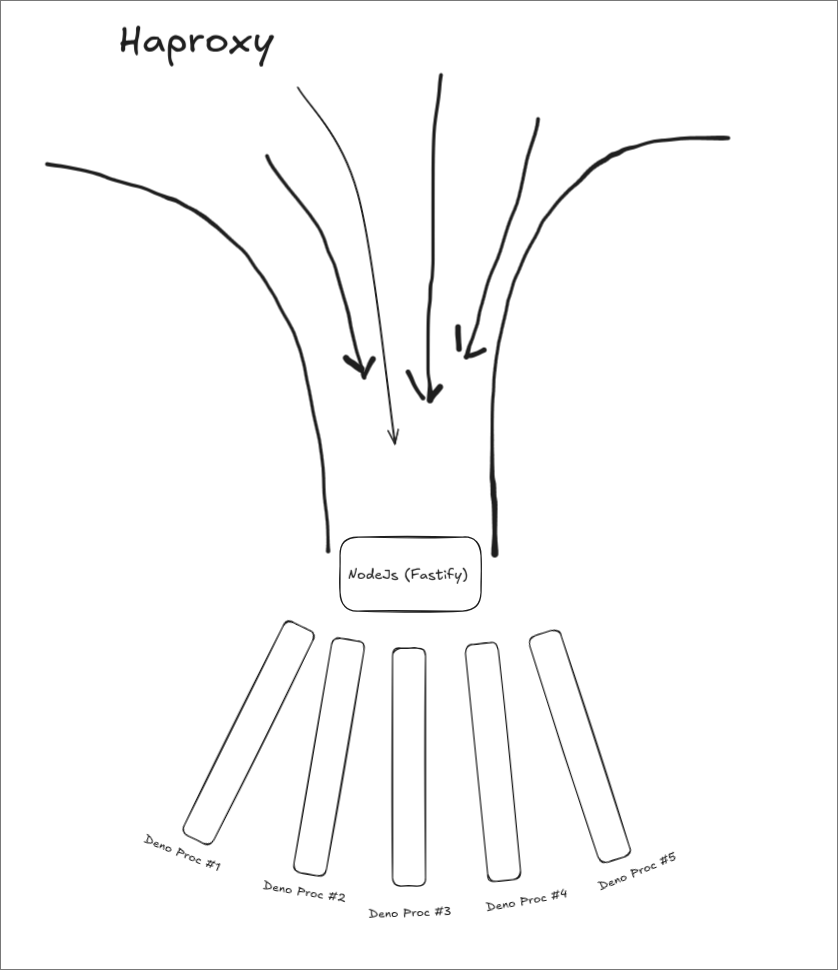
(Note that this is a bit simplified, since there are actually many nodejs servers behind haproxy, and requests are being consistent hashed to them)
Some context:
At Val Town, our request handling backend is pretty simple. We have a fastify server with a special endpoint for all user Val web requests. When a request comes in for a user’s Val, we consistent hash it to a server via haproxy, and then our nodejs server handles the request by either proxying to a warm Deno process (calling the user’s function), or spawning a new one, using our open-source deno-http-worker library.
As more requests come in, we spawn more processes, and the nodejs parent server is responsible for managing all children processes and keep track of state. But over time we’ve run into issues with loosing track of processes, failing to properly limit process utilization, and been bottlenecked by this single point of entry.
Right now, we’re single threaded. When a request comes in, our biggest bottleneck has been that we hit our database (postgres) to look up the Val’s metadata (like a URI to the actual source code, and environment variables).
This is a problem that we’ve needed to solve before thinking about making our server parallelized, and is the first step down the Project Banana path.
It might seem a bit complicated, but it’s really pretty simple. In order to run a Val, there’s a set of information that we typically query the database for, and that information stays static until the user edits the Val again in the future, or does things like change environmental variables, etc.
One point of complexity here, is that there’s a few servers for our API, and that means that if we are a given server, and we receive a request to edit a Val, we need to bust our cache, AND inform all other servers to bust theirs too.
My idea here was to just use a Postgres watch channel, so that we would not need to update our code everywhere to know that the cache should get busted. But we decided instead to use a Redis Pub/Sub approach, because we anticipate in the future that we may have too many servers such that it is too expensive to reserve so many Postgres connection pool seats.
In summary:
- When a request comes in, check the in-memory cache for the Val’s boot information (source code URI, env vars, etc) by hostname.
- If it’s there, proxy to the Deno worker with that information.
- If it’s not there, query the database for that information, store it in the cache, and then proxy to the Deno worker.
- If an edit request comes in, bust the cache for that hostname, and publish a message to Redis to inform other servers to do the same.
- And if we receive a Redis message to bust a cache, we do so.
It looks like this (ok, a little complicated :/):
Node, as a Banana!
Okay, so finally, we reach a point where we’re able to have a process where, sometimes, a request comes in to spawn a new Deno worker for a Val, and we DO NOT need to query the database. Awesome!
But we’re still bottlenecked.
Our actual nodejs server is single-threaded. And it turns out, spawning processes is pretty slow, and being single-threaded is definitely not helping. This is like, quite bad.
At higher loads (i.e., req/sec), we’re stuck — there’s a capable server that’s happy to run (possibly expensive) user code, it does not need to query the database, there’s already a nice warm worker, but our nodejs server simply cannot proxy the requests fast enough, because every request is going through a single “funnel”.
Making this worse is that our nodejs fastify servers are responsible for everyone’s Vals’ executions, so it is possible that if one person’s Val experiences a huge amount of traffic all of a sudden, that other peoples’ Vals that consistently hash to that server will also experience a slow down.
Enter the banana: splitting up work across threads with hostname specific
PID files for workers. With node:cluster, or even other server side Javascript
options (like
deno serve --parallel).
The name of this project comes from the idea that we’re transforming our single-threaded nodejs server into a cluster of many nodejs processes. When a request comes in for a worker, or to spawn a new one, some arbitrary nodejs process, of many, will be responsible for handling it, and then proxying the request. That banana process is also responsible for the worker’s lifecycle.
Sequential (Current)
Concurrent (Banana) 🍌 (round-robin)
But concurrency is hard.
We wanted to be able to accept many requests at once, but preserve a resilient
source of truth for our users’ processes. My idea was simple: cross-thread (err,
process, since node:cluster, discussed later, uses processes) communication in
node is hard and finicky, especially with complex and changing state. Why not,
instead, use the file system?
What cross-process communication looks like in node:cluster
import cluster from 'node:cluster';
import { cpus } from 'node:os';
import { createServer } from 'node:http';
if (cluster.isPrimary) { // Fork one worker per CPU const numCPUs =
cpus().length; for (let i = 0; i < numCPUs; i++) cluster.fork();
// Example: send message to all workers for (const id in cluster.workers) {
cluster.workers[id]?.send({ cmd: 'hello', from: 'primary' }); }
// Listen for messages from workers cluster.on('message', (worker, msg) => {
console.log(`Primary received from worker ${worker.id}:`, msg); }); } else { //
Each worker runs its own HTTP server const server = createServer((req, res) => {
process.send?.({ cmd: 'request', pid: process.pid });
res.end(`Handled by worker ${process.pid}\n`); });
// Listen for messages from primary process.on('message', (msg) => {
console.log(`Worker ${process.pid} got message:`, msg); });
server.listen(3000); }
Also, another aside: we were exploring writing this part of our server stack in
Deno, and deno does not even have any primitives for communication when using
deno serve --parallel, so this file system approach would be portable to Deno.
Files are nice and easy :)
To route processes to a javascript process manager, let’s just create a file with metadata about the process. And while we’re at it, why not make that the unix socket file too? I mean, we’ll need to make a unix socket file eventually, since we will at the end of the day be proxying requests to deno workers over unix sockets.
I actually had this initial crazy idea of storing the “boot information” in the name of the socket file itself (as a uri-encoded JSON), and we could rename the socket file to update the state, but it turns out there’s pretty strict limits to the length of unix filenames.
Okay, so let’s say that if we are a worker, and we receive a request, and we look and see that there’s a unix socket file in a folder that has the literal name being the hostname of the request we received, we are allowed to proxy. If we don’t, then we can delegate to a primary process that’s allowed to talk to the database, which can do the actual spawning, while we wait for it to finish and the needed unix socket file to come into existence.
It’s a little bit complicated when you start to actually think about how the system works, but here’s the general idea:
-
We have many nodejs workers, these are all forked from a primary nodejs process. We’ll see what this actually ends up looking like a little bit later (scroll ahead if you want to see code!)
-
When we spawn a deno worker for the first time, we may need to hit the database. We may not need to hit the database. It depends on if there’s a valid entry in cache. We actually can also store these entries on the file system, as long as we’re careful about deleting them. If we see an
-
We don’t want every single child process to sat up a database pool seat, so instead we forward the request to the primary process, which is the only process that is capable of actually hitting the database to get information necessary to spawn the deno process.
We’ve simplified it a bit, but that’s the general idea. Here’s a diagram!
Like we said above, in the diagram there’s three example requests, and they arrive in this timeline:
- An initial cold request for a.com, which requires spawning a new worker. In order to spawn the new worker the child process creates a lock for the hostname. It then asks the primary process for boot info, which it queries from the database, since there was no cached boot info (recall cached boot info just gets stored in a file). The primary process returns the boot info, and the child process spawns the worker, creating the unix socket file.
- An already warming request for a.com, which arrives while the first request is still spawning the worker. This process sees that there’s no socket file yet, and so it waits for it to appear (it could also ask the primary process for boot info, but that would be wasteful since another process is already spawning it).
- A warm request for b.com, which is the happy path. The child process sees that there’s already a socket file for b.com, and so it just proxies to it.
Going in Parallel
Okay so we have a general idea of how the system will work, at a high level. But how do we implement something like this — a proxying setup — in, err, server side javascript?
Well, to start, to do real parallelism in serverside JS land, there’s a few paths:
At Val Town, we love Deno! Deno makes super easy to make concurrent request
handlers with
deno serve --parallel!
Deno will:
- Automatically create multiple threads to handle user requests, and
- Round robins between them as requests roll in
export default {
async fetch(request) {
if (request.url.endsWith('/json')) {
return Response.json({ hello: 'world' })
}
return new Response('Hello world!')
},
} satisfies Deno.ServeDefaultExportNodejs has the same thing! But it’s built into the language, not a CLI feature.
This is what we hinted at earlier, and this is node’s
node:cluster module: a way to fork
multiple processes of the same server, and have them share incoming connections
by round robining.
It looks like this:
import cluster from 'node:cluster'
import http from 'node:http'
import os from 'node:os'
const numCPUs = os.cpus().length
if (cluster.isPrimary) {
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`)
})
} else {
// Workers can share any TCP connection.
// In this case, it is an HTTP server.
http
.createServer((req, res) => {
res.writeHead(200)
res.end('Hello world!')
})
.listen(8000)
}Of course, we're using fastify, so it's really more like this...
import cluster from 'node:cluster'
import os from 'node:os'
import Fastify from 'fastify'
const numCPUs = os.cpus().length
if (cluster.isPrimary) { // Fork workers. for (let i = 0; i < numCPUs; i++) {
cluster.fork() }
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`) }) } else { const fastify =
Fastify()
fastify.get('/', async (request, reply) => { return { hello: 'world' } })
fastify.listen({ port: 8000 }, (err) => { if (err) { console.error(err)
process.exit(1) } }) }
And, for good measure, Bun has its own super cool, Linux way to do this!
With Bun, you can take advantage of SO_REUSEPORT and SO_REUSEADDR socket
options to allow multiple processes to listen on the same port and address (crazy!).
Here’s the examples from their docs:
// server.ts
import {serve} from 'bun';
const id = Math.random().toString(36).slice(2);
serve({
port: process.env.PORT || 8080,
development: false,
// Share the same port across multiple processes
// This is the important part!
reusePort: true,
async fetch(request) {
return new Response('Hello from Bun #' + id + '!\n');
},
});// cluster.ts (spawns instances of server.ts)
import { spawn } from 'bun'
const cpus = navigator.hardwareConcurrency // Number of CPU cores
const buns = new Array(cpus)
for (let i = 0; i < cpus; i++) {
buns[i] = spawn({
cmd: ['bun', './server.ts'],
stdout: 'inherit',
stderr: 'inherit',
stdin: 'inherit',
})
}
function kill() {
for (const bun of buns) {
bun.kill()
}
}
process.on('SIGINT', kill)
process.on('exit', kill)And Bun also supports node:cluster!
(Deno does not).
And, since we have control of the code that the primary runs versus the workers, we can have the primary process be the only one that hits the database, while the workers just proxy to it when they need to spawn a new Deno worker for a Val.
We just conditionally grab a database connection!
Just for fun, you may recall that forking like this is quite similar to good old' C process forking
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() { int num_processes = 4; // Number of child processes to create for
(int i = 0; i < num_processes; i++) { pid_t pid = fork(); if (pid == 0) { //
Child process printf("Child process %d with PID %d\n", i, getpid()); exit(0); //
Exit child process } }
// Parent process waits for all child processes to finish
for (int i = 0; i < num_processes; i++) {
wait(NULL);
}
printf("All child processes have finished.\n");
return 0;
}
Just a little of an aside
But the point is, we now have many server side js processes, each capable of handling requests concurrently.
Now there’s a few more details we have to take care of.
First of all, when a request comes in, as we’ve talked about, we need to check whether there’s a worker for it. We said that we’re going to use the file system, and again, here that means that every running process is just a file in a folder. If the file exists, that means a worker is running, and that file can contain information about how to connect to that worker, or even just be the unix socket file itself.
But also, rather than checking every time we receive a request whether there is a running worker that is able to facilitate a request for the given hostname, why not just use file watchers, so we always have a correct idea of what files exist without having to make syscalls every single time a request comes in?
Pretty awesome!
We can use chokidar to watch a
directory for unix socket files to appear and disappear, and keep an in-memory
map of what files exist. These are our live workers! When a worker dies, it can
literally delete its own file!
We even can pre-connect to workers (like, open up a TCP pool) when we see a new socket file appear, so that when a request comes in, we can immediately proxy to it.
We know that if a file appears, that it was because either:
- We spawned a new worker (we had enough cache information to do so), or
- Another process spawned a new worker (just some other worker, we weren’t the one that did it)
- We asked the primary process to get us cache information so that we could spawn the worker, and it did so, and then we spawned the worker. Or that this was the case for some other worker.
For the rest of this blog though, we’ll ignore 3., and assume that if a nodejs process receives a request and there’s no socket file, it is the one that spawns it, adds it to its own memory state, and then proxies to it. If another process spawns a worker, then all other processes will see the socket file appear via the file watcher, and add it to their own memory state, and preconnect.
This is pretty elegant since we know that if the socket file appears, that since we’re round robining, some other worker spawned the worker, and we are likely to be the next one who’s going to proxy to it.
Let’s look at some code!
const conns = new Map<string, Pool>() // Map of hashed hostname to undici connection pool
// If it has a key in the map, then it has a file on disc!
watcher
.on('add', (path) => {
// If another worker creates a socket file, we create a new connection ahead of time
const socketId = socketPathToId(path) // We hash the hostname, since it turns out
// that the max size for a unix socket path is
// limited
conns.set(
socketId,
new Pool('http://localhost', {
socketPath: path,
connections: CONNECTIONS_PER_SOCKET,
}),
) // We're using undici's connection pool here. It's just a really nice HTTP client for node!
// Much faster, and with a better API than node's built-in http module
})
.on('unlink', (path) => {
const socketId = socketPathToId(path)
const pool = conns.get(socketId)
if (pool) {
pool.close()
conns.delete(socketId)
}
// If we spawned the worker, kill it
const proc = procs.get(socketId)
if (proc) {
proc.kill('SIGTERM')
proc.once('exit', () => {
clearTimeout(timeout)
console.log(`Worker for ${path} exited`)
})
procs.delete(socketId)
}
})And the actual worker server (the processes we’re spawning, which happen to also be javascript (Deno)) looks like this,
if (import.meta.url === Deno.mainModule) {
const pendingReqs = new pQueue()
Deno.serve(
{
path: Deno.args[0],
transport: 'unix',
},
async (request) => {
const resp = await pendingReqs.add(async () => await handler(request))
if (resp) {
return resp
} else {
return new Response('Internal Server Error', { status: 500 })
}
},
)
Deno.addSignalListener('SIGTERM', async () => {
await Deno.remove(Deno.args[0]) // Clean up the unix socket file
await pendingReqs.onIdle() // Wait for all pending requests to finish
Deno.exit(0)
})
}Noting that
- We want to keep track of all requests we’ve received, so that when we are SIGTERM’d we can wait for them to finish (we just use a simple promise queue to make it easy)
- We also want to clean up the unix socket file when we exit, so the processes observe that we are no longer reachable and stop proxying to us.
If a deno process dies, then all the nodejs processes will see the socket file go away and clean up their own memory state.
Ironing it Out
We’re not quite done yet though! There’s a few more details to iron out.
Now that we’re running concurrent nodejs processes, it is totally possible for multiple processes to try and access the same resources at the same time. This can lead to all sorts of no-fun issues, like two workers being spawned at the same time, which wastes resources and slows us down. This is the case when two network requests come in on the same tick. That wouldn’t normally be an issue in a single-threaded server, since requests are handled one at a time, but now that we have multiple processes, it is totally possible.
Okay, so back to my linux brain “just use the file system” mindset.
Yes, we could use Redis locks.
Let's just use the file system... for locks!
/**
* Try to acquire a lock for a path, running the appropriate callback based on
* whether the lock was acquired or already held.
*
* @param args.path The path to the socket file.
* @param args.onAlreadyExists Callback to run if the target already exists.
* @param args.onAcquired Callback to run if the lock is acquired.
* @param args.onAlreadyHeld Callback to run if the lock is already held.
*/
async function tryLockFile<T>({
target,
onAlreadyExists,
onAcquired,
onAlreadyHeld,
}: {
target: string;
onAlreadyExists: () => Promise<T>;
onAcquired: () => Promise<T>;
onAlreadyHeld: () => Promise<T>;
}): Promise<T> {
let acquiredLock = false;
try {
await fs.access(target);
return await onAlreadyExists();
} catch {
console.log(`Socket file ${target} does not exist, spawning worker...`);
try {
await fs.mkdir(`${target}.lock`);
acquiredLock = true;
return await onAcquired();
} catch (e) {
if (!(e instanceof Error && e.message.includes("EEXIST"))) throw e;
console.log(`Socket file ${target} is being created`);
// Already held
}
console.log(`Socket file ${target} is being created by another worker...`);
return await onAlreadyHeld();
} finally { if (acquiredLock) { // Remove the lock directory await
fs.rmdir(`${target}.lock`); } } }
We can literally just create a folder right before we spawn a new worker, and delete it right after. If another process tries to create the same folder at the same time, it will fail, and we can just wait for the socket file to appear instead.
So finally, putting the pieces together, when a request comes in, we do this:
async function getConnPool(socketPath: string) {
const socketId = socketPathToId(socketPath);
const existingConn = conns.get(socketId);
if (existingConn) {
console.log(`Reusing existing connection for ${socketPath}`);
return existingConn;
}
await tryLockFile({
target: socketPath,
onAlreadyExists: async () => {
conns.set(
socketId,
new Pool("http://localhost", {
socketPath: socketPath,
connections: CONNECTIONS_PER_SOCKET,
}),
);
},
onAcquired: async () => {
// File doesn't exist, spawn the worker
const proc = spawn(
"deno",
[
"run",
"-A",
"--node-modules-dir=false",
join(WORKERS_DIR, "worker.ts"),
socketPath,
],
{ stdio: "pipe" },
);
await waitForWatcherEvent("add", socketPath);
proc.once("exit", async (code, signal) => {
console.log(
`${socketPath} exited with code ${code}, signal ${signal}`,
);
procs.delete(socketId);
conns.delete(socketId);
await fs.rm(socketPath, { force: true });
});
proc.stdout.on("data", (data) => injesterTcp.write(data));
proc.stderr.on("data", (data) => {
const text = new TextDecoder("utf-8");
console.error(text.decode(data));
});
procs.set(socketId, proc);
conns.set(
socketId,
new Pool("http://localhost", {
socketPath: socketPath,
connections: CONNECTIONS_PER_SOCKET,
}),
);
},
onAlreadyHeld: async () => {
await waitForWatcherEvent("add", socketPath);
conns.set(
socketId,
new Pool("http://localhost", {
socketPath: socketPath,
connections: CONNECTIONS_PER_SOCKET,
}),
);
},
});
const conn = conns.get(socketId);
if (!conn) {
throw new Error(`Failed to get connection pool for ${socketPath}`);
}
return conn;
}waitForWatcherEvent is just like it sounds
/**
* Wait for a file system watcher event.
*
* @param event The event to wait for.
* @param path The path to watch.
* @returns A promise that resolves when the event occurs.
*/
function waitForWatcherEvent(
event: keyof FSWatcherEventMap,
path: string,
): Promise<void> {
return new Promise<void>((res) => {
const handler = (eventPath: string) => {
if (resolve(eventPath) === resolve(path)) {
watcher.off(event, handler)
res()
}
}
watcher.on(event, handler)
})
}Note that chokidar will batch events together and uses real inotify, so this
is actually quite efficient.
Okay, so now we have a concurrent nodejs server that can handle many requests at once, and spawn deno workers as needed.
When we get a flood of requests, we can now handle them all concurrently, and should have an open TCP connection ahead of time so we can snappily proxy.
Numbers!
Here’s some metrics from testing with my favorite network stress tester (oha).
We tested with and without keepalive (from the client), since in we’re worried about the case where many clients are connecting to the same Val (worker) at once, and thus are not keeping connections alive.
I also tested with different %s of requests being unique hostnames (i.e. 10% being unique hostnames), where the rest are hitting warm workers, and the actual spawning was uniformly distributed. The idea is that with less unique hostnames, most requests are going to warm workers, so we should see the biggest benefits from multiprocessing. Likewise, with more unique hostnames, more requests require spawning, which is probably even slower now that we have lock contention.
All the table entries are in requests per second.
300 Concurrent Connections w/o Keepalive
| % New Workers | 10 Workers | 8 Workers | 1 Worker |
|---|---|---|---|
| 2.00 | 2631 | 1848 | 1439 |
| 7.00 | 1025 | 1096 | 704 |
| 10.00 | 823 | 808 | 547 |
| 15.00 | 453 | 502 | 372 |
| 20.00 | 641 | 362 | 295 |
100 Concurrent Connections w/ Keepalive
| % New Workers | 10 Workers | 8 Workers | 1 Worker |
|---|---|---|---|
| 2.00 | 3296 | 3555 | 1960 |
| 7.00 | 2351 | 2473 | 2273 |
| 10.00 | 840 | 404 | 976 |
| 15.00 | 412 | 310 | 520 |
| 20.00 | 311 | 203 | 329 |
In general, things look great! When we test at high concurrency with high new worker spawn rate, for all keepalive connections we see that the process spawning is actually pretty detrimental, but we’re still competitive. In other cases, the benefits are super clear cut!
One final note about these numbers — for actually simulating load (since, for example, a simple hello world http server is not particularly realistic), we set up a simple raw TCP server that we, on each request, would send a bunch of bytes into, to do some blocking IO. This is somewhat realistic, since Vals, as they run, are sending along data to ClickHouse in production.
Extras
Now here’s my dump of some fun additional things that came out of the research
WebSockets!
First off all, now that the parent process is not the one managing all connections, we’re much more primed to start handling WebSocket connections!
Where previous the parent would need to be responsible for maintaining all the TCP connections to Deno workers, now that each worker process is managing its own connections, we can distribute it.
It’s a bit weird to actually do with fastify. That’s because node’s built-in
HTTP server does not natively support WebSockets, but it gives you the ability
to respond to upgrade requests, (which makes sense, since this is just part of
the HTTP spec).
That “responding to upgrade requests” part is a bit tricky because it requires a
WebSocket handshake, but thankfully there’s a library that handles the framing
and handshake for you, ws.
When doing it manually with the upgrade callback and nodejs http, it looks
like this:
import http from 'http'
import WebSocket, { WebSocketServer } from 'ws'
const server = http.createServer()
const wss = new WebSocketServer({ noServer: true })
server.on('upgrade', (request, socket, head) => {
// the magic function!
// | |
wss.handleUpgrade(request, socket, head, (ws) => {
ws.send('Hello World!')
ws.on('message', (data) => {
console.log('Received:', data.toString())
ws.send(`Echo: ${data}`)
})
})
})
server.listen(8080, () => {
console.log('Server listening on port 8080')
})Under the hood, fastify uses node http too. There’s a plugin that handles this
for us, which is
fastify-websocket.
There’s one issue though. According to their GitHub, using it looks like this:
fastify.register(async function () {
fastify.route({
method: 'GET',
url: '/hello',
handler: (req, reply) => {
// this will handle http requests
reply.send({ hello: 'world' })
},
wsHandler: (socket, req) => {
// this will handle websockets connections
socket.send('hello client')
socket.once('message', (chunk) => {
socket.close()
})
},
})
})But we’re just a proxy! We want to forward all requests, whether HTTP or
WebSocket, to the Deno worker, and irrespective of the path. Having to register
for a path is a big no-no. If we just register the WebSocket server on *, then
fastify will not know how to handle normal HTTP requests.
So what’s the solution? Just use a hook to intercept requests before they hit the handler, so by the time we’re using the WebSocket handler we know all requests must be real WebSocket requests. It’s a bit jank, but it does work.
To actual do the upgrade, we just wire our callbacks to our pool's, so that when we receive a message via our WebSocket it just directly pumps to the Deno worker's WebSocket, and vice versa.
// pool is some undici Pool connected to the Deno worker
const webSocketToUpstream = new WebSocket(`ws:${socketPath}:${req.url}`, {
dispatcher: pool,
headers: Object.fromEntries(
// filter out websocket-specific headers, since ws library adds them automatically
Object.entries(req.headers)
.filter(
([key]) =>
![
// don't include websocket-specific headers
'connection',
'upgrade',
'sec-websocket-version',
'sec-websocket-key',
].includes(key.toLowerCase()),
)
.map(([key, value]) => [
key,
Array.isArray(value) ? value.join(', ') : value || '',
]),
),
})
const websocketToUs = socket // this is given to us in our WebSocket handler
// Really, it's pretty stupid simple -- just pipe messages back and forth
webSocketToUpstream.addEventListener('message', (event) => {
websocketToUs.send(event.data) }) websocketToUs.addEventListener('message',
(event) => { webSocketToUpstream.send(event.data as any) })
websocketToUs.addEventListener('close', () => { webSocketToUpstream.close() })
And, all put together, WebSocket support looks like this:
const fastify = Fastify()
fastify.register(fastifyWebsocket)
fastify.decorateRequest('socketPath', '')
fastify.addHook('preHandler', async (req, resp) => {
// Skip websocket requests
if (req.headers.upgrade === 'websocket') {
return // fall through to websocket handler
} else {
// ...
// Proxy normal HTTP requests by grabbing the pool and forwarding
// ...
}
})
await fastify.register(async () => {
fastify.get(
'*',
{
websocket: true,
},
async (socket, req) => {
const pool = await getConnPool(req.socketPath) // warm the worker
const denoSocket = new WebSocket(`ws:${req.socketPath}:${req.url}`, {
dispatcher: pool,
headers: Object.fromEntries(
Object.entries(req.headers)
.filter(
([key]) =>
![
// don't include websocket-specific headers
'connection',
'upgrade',
'sec-websocket-version',
'sec-websocket-key',
].includes(key.toLowerCase()),
)
.map(([key, value]) => [
key,
Array.isArray(value) ? value.join(', ') : value || '',
]),
),
})
denoSocket.addEventListener('message', (event) => {
socket.send(event.data)
})
socket.addEventListener('message', (event) => {
denoSocket.send(event.data as any)
})
socket.addEventListener('close', () => {
console.log('WebSocket closed, closing Deno socket')
denoSocket.close()
})
},
)
})
fastify.listen({ port: 8000 }, () => {
console.log(`Worker listening on port 8000, PID: ${process.pid}`)
})Docker
Just for fun, we also tried running our Workers in their own Docker containers.
This really just was using the docker -a=STDIN -a=STDOUT -a=STDERR -i flags to
keep stdin open and attach to the appropriate streams. Then we could just spawn
the container, and pipe commands to its stdin to have it spawn Deno processes
inside the container.
I was a little fancy, and also set up pooling so that we could always have warm deno processes ready!
I packaged this into a nice class that could maintain the pools, so that the final implementation just looked like (below):
import { spawn } from "node:child_process";
import { createInterface } from "node:readline";
import { basename, join, resolve } from "node:path";
import { Readable } from "node:stream";
import { EventEmitter } from "node:events";
import { rm } from "node:fs/promises";
import { createHash } from "node:crypto";
const CONTAINER_SOCKETS_DIR = "/var/run/sockets";
interface LogMessage { src: string; msg: string; }
interface DenoContainerArgs { containerTag: string; socketsDir: string; }
interface ContainerEvents { /\*_ Exit code and module URL _/ exit: [number |
null, string?]; log: [LogMessage]; }
/\*\*
- A DenoContainer manages a single Docker container running a Deno supervisor
process.
-
- The supervisor process listens for JSON payloads on stdin to spawn Deno
processes
- that run user-provided modules.
-
- .spawn() - starts the Docker container and supervisor process
- .stop() - stops the current running module (if any) but keeps the container
alive
- .run() - sends a JSON payload to the supervisor to run a specific module with
env \*/ export class DenoContainer extends EventEmitter<ContainerEvents> {
public id: string | null = null;
#proc!: ReturnType<typeof spawn>; #currentModuleUrl: string | null = null;
#containerTag: string; #socketsDir: string; #stdout: Readable; #stderr:
Readable;
constructor({ containerTag, socketsDir }: DenoContainerArgs) { super();
this.#containerTag = containerTag; this.#socketsDir = resolve(socketsDir);
this.#stdout = new Readable({
read() {}, // No-op, data is pushed via events
});
this.#stderr = new Readable({
read() {}, // No-op, data is pushed via events
});
}
/\*\*
- Readable stream of the container's running modules' stdout (from the
supervisor process). \*/ public get stdout(): Readable { return this.#stdout;
}
/\*\*
- Readable stream of the container's running modules' stderr (from the
supervisor process). \*/ public get stderr(): Readable { return this.#stderr;
}
public async spawn() { const DENO_DIR = process.env.DENO_DIR;
this.#proc = spawn(
"docker",
[
"run",
...["-v", `${DENO_DIR}:/root/.cache/deno`],
...["-v", `${this.#socketsDir}:${CONTAINER_SOCKETS_DIR}`],
"--env",
`DOCKER_ID=${this.id}`,
"--rm", // remove container after exit
"-i", // keep stdin open
"-a=STDIN", // attach stdin, stdout, and stderr
"-a=STDOUT",
"-a=STDERR",
this.#containerTag,
],
{ stdio: ["pipe", "pipe", "inherit"] },
);
this.#proc.on("spawn", () => {
console.log("Spawned container");
});
this.#waitForSupervisorLine((parsed) =>
parsed.src === "main" &&
parsed.msg.startsWith("exit")
)
.then(({ msg }) => {
const exitCodeStr = msg?.split(" ")[1];
const exitCode = exitCodeStr ? Number.parseInt(exitCodeStr) : null;
this.emit(
"exit",
exitCode || null,
this.#currentModuleUrl || undefined,
);
});
createInterface({
input: this.#proc.stdout!,
crlfDelay: Number.POSITIVE_INFINITY,
}).on("line", (line) => {
const parsed = JSON.parse(line);
if (parsed.src === "stdout") {
this.#stdout.push(`${parsed.msg}\n`);
} else if (parsed.src === "stderr") {
this.#stderr.push(`${parsed.msg}\n`);
}
console.log(`[container ${this.id}]`, parsed);
this.emit("log", parsed);
});
await this.#waitForSupervisorLine(
(parsed) => parsed.src === "main" && parsed.msg === "starting",
);
}
public async stop() { if (this.#proc) { this.#proc.kill("SIGUSR1"); // Kill the
child, but keep the docker container running }
await this.#waitForSupervisorLine(
(parsed) => parsed.src === "main" && parsed.msg === "stopped",
);
}
public async run({ moduleUrl, envVars = {}, cwd = "/app", }: { moduleUrl:
string; envVars: Record<string, string>; cwd: string; socketName: string; }) {
this.id = moduleUrl; this.#currentModuleUrl = moduleUrl; const input =
`${ JSON.stringify({ moduleUrl, envVars, cwd, socketPath: socketPathToUse(CONTAINER_SOCKETS_DIR, moduleUrl), }) }\n`;
this.#proc.stdin?.write(input);
await this.#waitForSupervisorLine(
(parsed) => parsed.src === "main" && parsed.msg === "spawned",
);
}
async #waitForSupervisorLine( stop: (msg: LogMessage) => boolean, ):
Promise<LogMessage> { return new Promise((res) => { const onLog = (log:
LogMessage) => { if (stop(log)) { this.off("log", onLog); res(log); } };
this.on("log", onLog);
});
} }
/\*\*
- A pool of DenoContainers that can be reused to run different modules. \*/
export class DenoContainerPool { #availablePool: DenoContainer[] = [];
#inUsePool: Map<string, DenoContainer> = new Map();
#containerTag: string; #socketsDir: string;
constructor(initialCount: number, containerTag: string, socketsDir: string) {
this.#containerTag = containerTag; this.#socketsDir = resolve(socketsDir);
// Preload containers
this.#preloadContainers(initialCount);
}
public async getContainer(moduleUrl: string): Promise<DenoContainer> { // Check
if we already have a container for this module URL const existingContainer =
this.#inUsePool.get(moduleUrl); if (existingContainer) { return
existingContainer; }
let container: DenoContainer | undefined;
if (this.#availablePool.length > 0) {
container = this.#availablePool.pop();
}
if (!container) {
console.log("No available containers, creating a new one...");
// Create and spawn a new container if none available
container = new DenoContainer({
containerTag: this.#containerTag,
socketsDir: this.#socketsDir,
});
await container.spawn();
}
this.#inUsePool.set(moduleUrl, container);
// Set up recycling when container exits
container.once("exit", async (code, exitModuleUrl) => {
console.log(`Container for ${exitModuleUrl} exited with code ${code}`);
if (!exitModuleUrl) return;
console.log(`Recycling container for ${exitModuleUrl}`);
try {
this.#inUsePool.delete(exitModuleUrl);
await container.stop();
await rm(socketPathToUse(this.#socketsDir, exitModuleUrl));
await container.spawn();
this.#availablePool.push(container);
} catch (error) {
console.error("Failed to recycle container:", error);
}
});
return container;
}
async #preloadContainers(count: number): Promise<void> { const containers =
await this.#getNContainers(count);
for (const container of containers) {
this.#availablePool.push(container);
}
}
async #getNContainers(n: number): Promise<DenoContainer[]> { return Promise.all(
Array.from({ length: n }, async () => { const container = new DenoContainer({
containerTag: this.#containerTag, socketsDir: this.#socketsDir, }); await
container.spawn(); return container; }), ); } }
export function socketPathToUse(socketsDir: string, moduleUrl: string): string {
// Socket paths cannot be over 108 characters, so we hash it down
const hashedPathName = createHash("sha256")
.update(basename(moduleUrl))
.digest("hex")
.slice(0, 6);
return join(socketsDir, `${hashedPathName}.sock`); }
fastify.all("*", async (req, resp) => {
const { moduleUrl } = req.query as { moduleUrl: string };
// Instead of hostname, we're using some query parameter to identify the Val.
// This is sort of arbitrary.
const socketPath = socketPathToUse(SOCKETS_DIR, moduleUrl);
// socketPathToUse just hashes the hostname, since the length needs to be
// short for unix socket file path names (just an antiquated rule)
//
// https://unix.stackexchange.com/questions/367008/why-is-socket-path-length-limited-to-a-hundred-chars
const pool = await getConnPool(socketPath, moduleUrl);
const denoResp = await pool.request({
method: req.method,
path: req.url,
headers: req.headers,
body: req.body as Readable,
});
console.log(`Forwarded request to worker for ${req.url}`);
resp.status(denoResp.statusCode);
Object.entries(denoResp.headers || {})
.forEach(([key, value]) => resp.header(key, value));
Object.entries(denoResp.trailers || {})
.forEach(([key, value]) => resp.trailer(key, () => value));
return resp.send(denoResp.body);
});And getConnPool just looks like this (recall from earlier that we have to be
careful about locks to prevent concurrently spawning multiple workers for the
same Val):
async function getConnPool(socketPath: string, moduleUrl: string) {
const existingConn = conns.get(socketPath)
if (existingConn) {
return existingConn
}
await tryLockFile({
target: socketPath,
onAlreadyExists: async () => {
conns.set(
socketPath,
new Pool('http://localhost', {
socketPath: socketPath,
connections: 50,
}),
)
},
onAcquired: async () => {
// Get a container from the pool (creates new one if needed)
const container = await containerPool.getContainer(moduleUrl)
console.log(`Acquired container for ${basename(socketPath)}`)
void container.run({
moduleUrl,
envVars: CONTAINER_ENV_VARS,
cwd: '/app',
socketName: basename(socketPath),
})
container.stdout?.pipe(process.stdout, { end: false })
container.stderr?.pipe(process.stderr, { end: false })
await waitForWatcherEvent('add', socketPath)
console.log(`Spawned worker for ${socketPath}`)
conns.set(
socketPath,
new Pool('http://localhost', {
socketPath: socketPath,
connections: 50,
}),
)
},
onAlreadyHeld: async () => {
await waitForWatcherEvent('add', socketPath)
conns.set(
socketPath,
new Pool('http://localhost', {
socketPath: socketPath,
connections: 50,
}),
)
},
})
const conn = conns.get(socketPath)
if (!conn) {
throw new Error(`Failed to get connection pool for ${socketPath}`)
}
return conn
}One more trick we can use here to make sure that there’s always warm workers is, when we spawn a worker, to spawn a new container ahead of time in the background, so that we’re always able to handle new requests (up to a limit).
Deno
Okay, finally, we redid the whole thing in Deno with deno serve --parallel
flag for good measure.
The notable differences were:
-
We can use Deno’s built-in file system watcher for our helpers instead of
chokidar. -
We can use Deno’s built-in HTTP client with unix socket support instead of
undici. It’s really really easy!const pool = Deno.createHttpClient({ proxy: { path: socketPath, transport: 'unix' }, }) // And then we can just use fetch with the client! const resp = await fetch('http://localhost/some/path', { method: 'GET', client: pool, })At the time I was working on this project, Deno’s HTTP client did not support WebSockets, but they actually added it recently!!
And put together, it looks like this:
export default {
async fetch(req) {
const pathname = new URL(req.url).pathname
const socketId = socketPathToId(pathname)
const socketPath = join(SOCKETS_DIR, `${socketId}.sock`)
const client = await getConn(socketPath)
const resp = await fetch(`http://localhost${pathname}`, {
method: req.method,
headers: req.headers,
body: req.body,
client,
})
return resp
},
} satisfies Deno.ServeDefaultExport
async function getConn(socketPath: string) {
const socketId = socketPathToId(socketPath)
const existingConn = conns.get(socketId)
if (existingConn) return existingConn
await tryLockFile({
path: socketPath,
onAlreadyExists: async () => {
conns.set(
socketId,
Deno.createHttpClient({
proxy: { path: socketPath, transport: 'unix' },
}),
)
},
onAcquired: async () => {
const proc = new Deno.Command(Deno.execPath(), {
args: ['run', '-A', '../workers/worker.ts', socketPath],
stdout: 'inherit',
stderr: 'inherit',
}).spawn()
await waitForWatcherEvent('add', socketPath)
procs.set(socketId, proc)
},
onAlreadyHeld: async () => {
await waitForWatcherEvent('add', socketPath)
},
})
const client = Deno.createHttpClient({
proxy: { path: socketPath, transport: 'unix' },
})
conns.set(socketId, client)
return client
}You made it to the end! Hopefully this was interesting!