I’ve Done Everything
Last Tuesday, on July 2nd, 2024, I implemented everything in python. There is literally nothing left to implement, I’ve now done it all.
Here is the Github and the PyPi
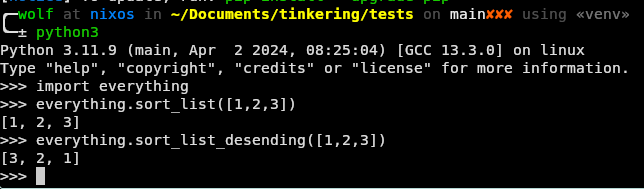
And here’s a real world demo…
from everything import sort_list, stylized_greeting
# Print a greeting for Wolf
print(stylized_greeting("Wolf", "Angry"))
# Sort a list
print(sort_list([3, 2, 1, 0, -5, 2.5]))>> pip install dothething
>> OPENAI_API_TOKEN=...
>> python example.py
WHAT DO YOU WANT, WOLF?!
[-5, 0, 1, 2, 2.5, 3]It is, in a word, everything.
Inspiration
The idea hit out of the blue, quite literally, in a conversation with a friend about abstractions for parallel computing. It hit me, why not be able to use your own abstractions created on a whim at runtime?
How’s it work?
When you import <anything> from everything, dothething will use Python’s AST library to scan your source code, and find all usages of <anything>. I’ve defined methods that will search for all usages of given functions, and can then grab parts of the code. Python’s AST library is really nice because it provides line numbers with references to the exact location in the source code of different elements. It then will merge a few lines of context on both sides of every function call, along with the call itself. Then, it will use OpenAI’s gpt-4o model to generate a Python function, which you can then use in your code.
It also works in a repl, and scans the history of the interactive shell to see
if there’s any relevant context. This part is a bit glitchy, and is probably
shell and terminal dependent to some extent. It’s using python’s readline
library to get access to shell environment stuff.
Execs
To actually bring the LLM code into the codebase, I’m using exec and a
context, where I dump the function into a localized environment and then wrap
the function, and call the resulting function with the wrapper. Here’s where I
actually inject the LLM code…
function_name = re.findall(r"def (\w[\w\d]+)\(", generated_function.split("\n")[0])
function_name = function_name[0] if function_name is not None else "error"
_LOGGER.debug(f"Function generated had name {function_name}")
def the_thing(*args, **kwargs):
exec(generated_function)
context = locals()
exec(f"result = {function_name}(*args,**kwargs)", context)
return context["result"]Dynamic Imports
To actually handle being able to import anything, under the hood I’ve modified
the module’s __getattr__, so that it can create the function when it is
imported. My __init__.py for the module looks something like this…
# __init__.py
"""Top-level package for everything."""
__author__ = """Wolf Mermelstein"""
__email__ = "wolfmermelstein@gmail.com"
__version__ = "0.1.0"
def __getattr__(name: str):
from .makethething import make_the_thing
return make_the_thing(name)__init__.py files are files that are a directive to python that a given folder
is a module, and they are run when you load the module.
Because of how module caching works, if you import the same name in different places in your project, it will only generate the function once and then will reuse it multiple times.

But, as it turns out, this is a relatively new feature that was added in
PEP562 (PEP = project enhancement
protocol). Previously, you had to rely on a hack that the creator of Python
himself suggested, overwriting the module with a class that overrides the
__getattr__.
"""Top-level package for everything."""
__author__ = """Wolf Mermelstein"""
__email__ = "wolfmermelstein@gmail.com"
__version__ = "0.1.0"
from typing import Callable
from everything.generator import runtime_generate_function
import sys
class Everything:
def __getattr__(name: str) -> Callable:
return runtime_generate_function(name)
sys.modules[__name__] = Everything()Next Steps
Now that it’s working, I’ve had the idea to take it to the next level by adding
a compilation step. Basically, I want to be able to import everything
throughout my codebase, and even submodules like everything.finance.irr, and
have my program build a library for you based on the way you use it.
The idea is that you can use a library that doesn’t exist as you want, and then
everything can “poof” it into existence by running something like
everything build. It would generate a everything folder with all the content
in it, so you could modify the code if necessary (but that’s against the spirit
of the library).
Improvements
There’s a lot of open questions on what I’d need to do to get this to work, and how I can make it better. For one, I want to figure out how to give OpenAi generated functions access to arbitrary Python libraries on PyPi. I also want to be able to lint and verify the code, and black the code to format it.
Naming
So, I was thinking, wouldn’t it be so awesome if you literally could
pip install everything? Currently it’s
dothething on PyPi, which is kinda lame.
I looked into it, and it appears that everything was not taken on PyPi!
However, it’s reserved, probably to prevent name hoarding or abuse. I did a lot
of research on this, and found out about
PEP 541, which is an approved Python PEP
(project enhancement proposal) for reclaiming unused or unmaintained namespaces
on PyPi. I made a request here,
as a github issue, which is the method they suggest, and am currently waiting to
hear back.
A bit more research scanning similar requests though, it doesn’t seem like PyPi
really handles 541 requests anymore. The requests pile up, but only the admins
can actually resolve them. This led me on a search to try to find an admin that
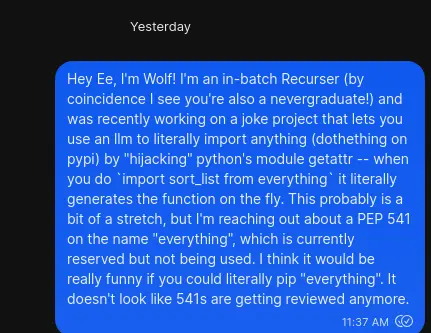
I might be able to contact directly to get the name everything. After a bit of
searching, I found Ee, the head of infrastructure for the Python Foundation, and
learned that he was a Recurse Center alum too. I reached out to him to see if
he’d be able to help, and current am waiting for a response.